本文希望从 Base-Attention 到 Transformer 逐层递进的解释其中的计算细节,从而更好的理解 Transformer 模型。本文主要对模型可能存在的盲区进行解释,可能思路有些跳跃,请谅解。参考资料见文章末尾Reference.
Base-Attention
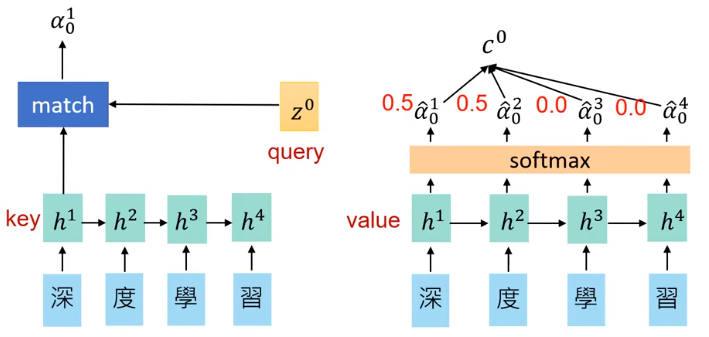
如左图所示,为了实现Attention机制,我们需要一个 Z0Z0,与 h1h1 计算得到一个scaleα10α01,这个 α10α01 可以简单看做 hh 与 zz 的相似度.
将 Z0Z0 与每一个 hihi 进行相乘然后 SoftmaxSoftmax 计算得到distribution αi0α0i,就变成了右图。这个distribution就是Attention机制的Weight。得到Attention之后将αi0α0i 乘上 hihi 后加到一起形成VectorC0C0,C0C0 就是预测第一个单词的特征向量。
注:本例中的Value是与Key相同的,但是实际上Value可以与Key不同,因为Key是用来计算Attention的Weightαα 的,而Value是用来与 αα 相乘得到Vector的,因此Key与Value不需要一定相同。

Dot-Product Attention是 Base 的一种计算方式,图中表示了 Attention 的计算公式以及相对应的 Q,K,VQ,K,V 的维度。
Self-Attention
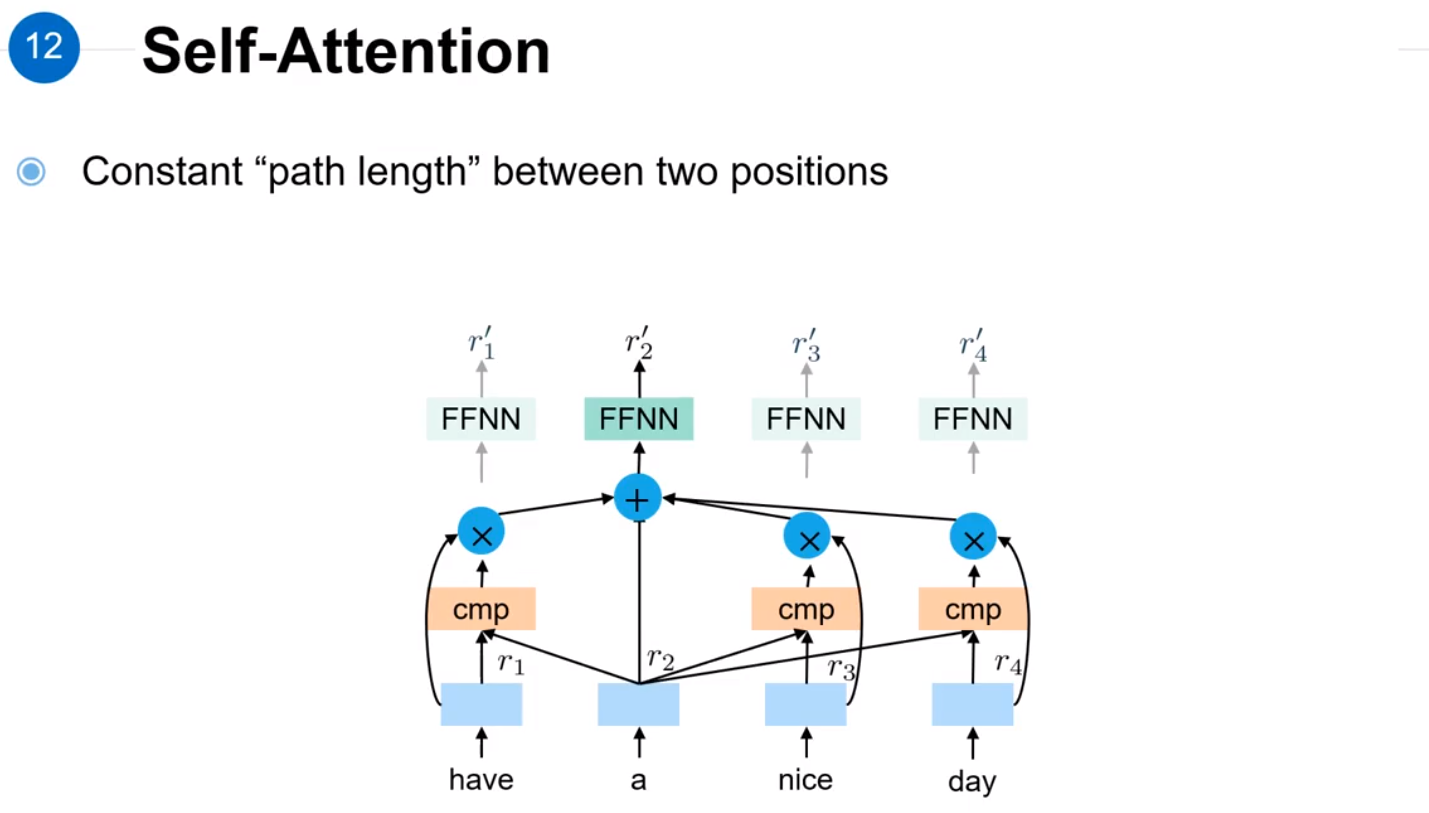
Self-Attention主要解决了训练时的并行问题,计算每个单词Attention时不用等前一个单词计算完成即可开始计算,以图中a为例。
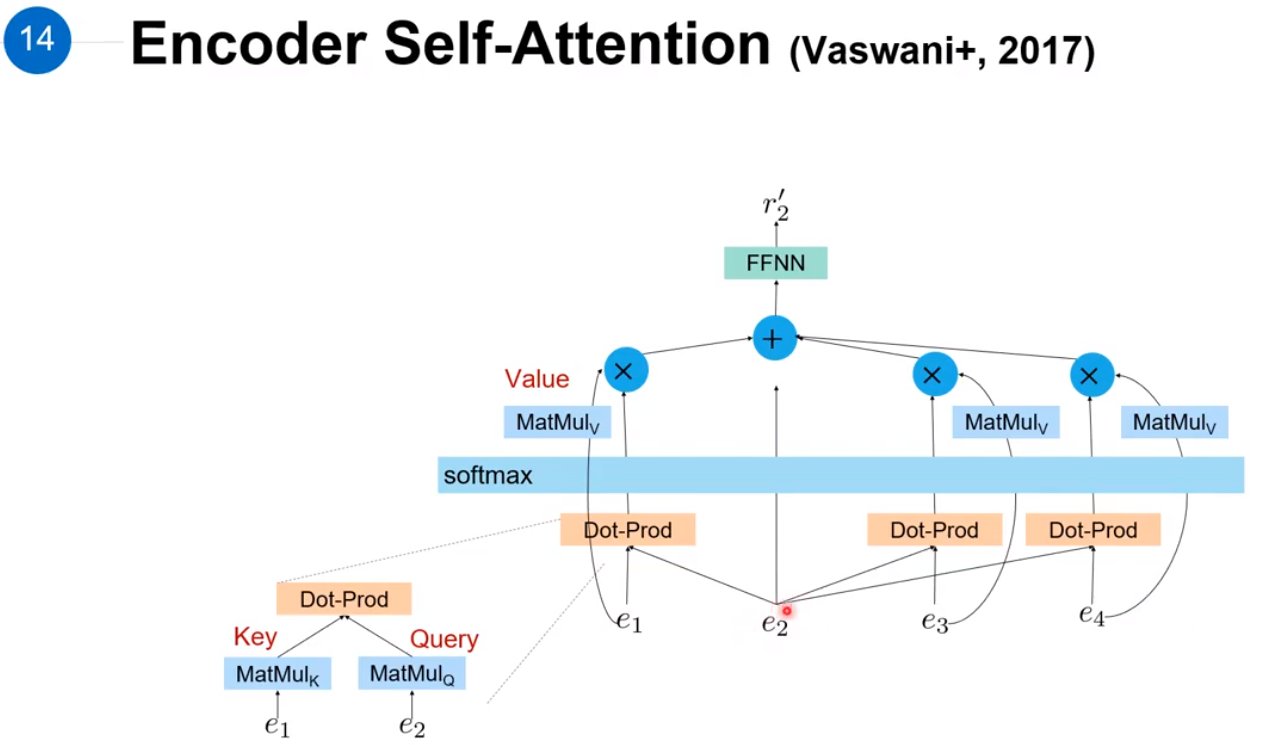
如图以 e2e2 为例,把自身的vector作为Query,Dot-Product 的Key就是 e1e1。
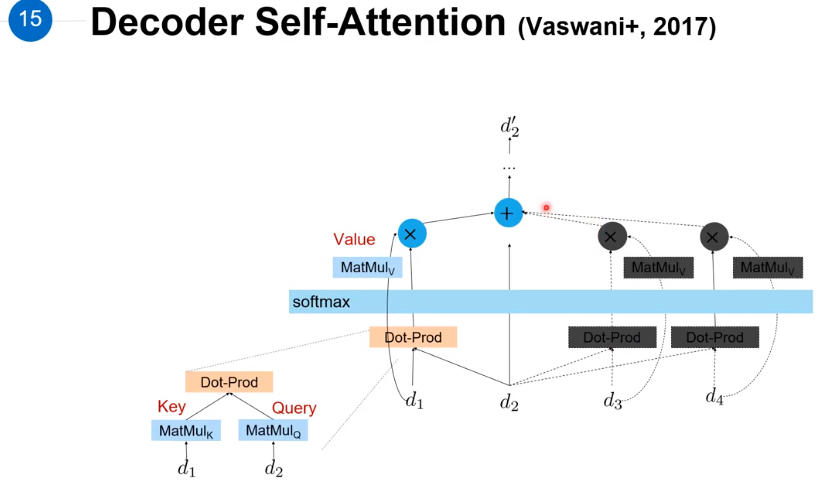
而在 decoder 的时候需要把 e2e2 后面的词给 mask 掉,因为inference阶段是没有后面输入。
Multi-Head Attention
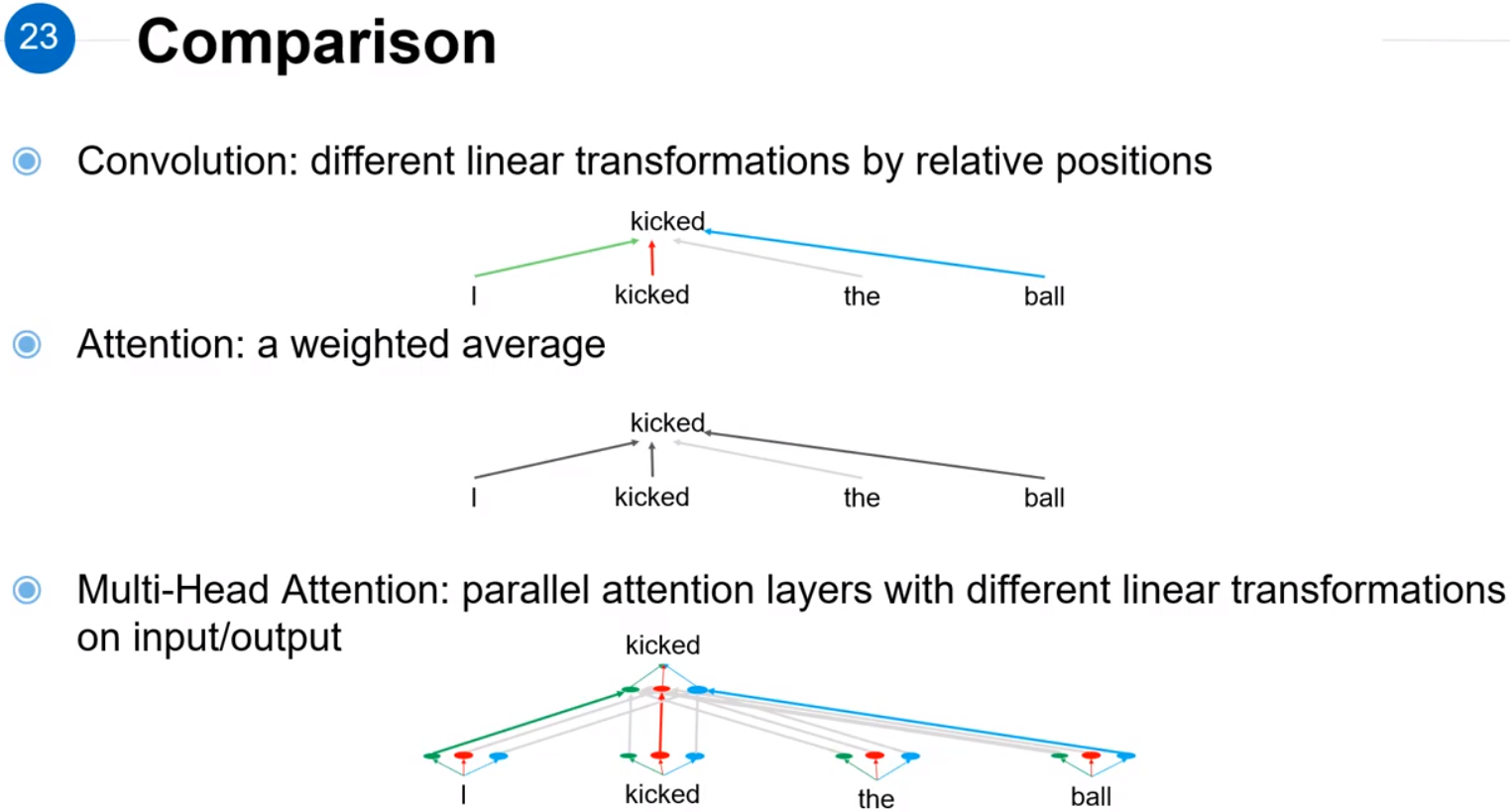
对Multi-Head Attention的相关解释如图所示。
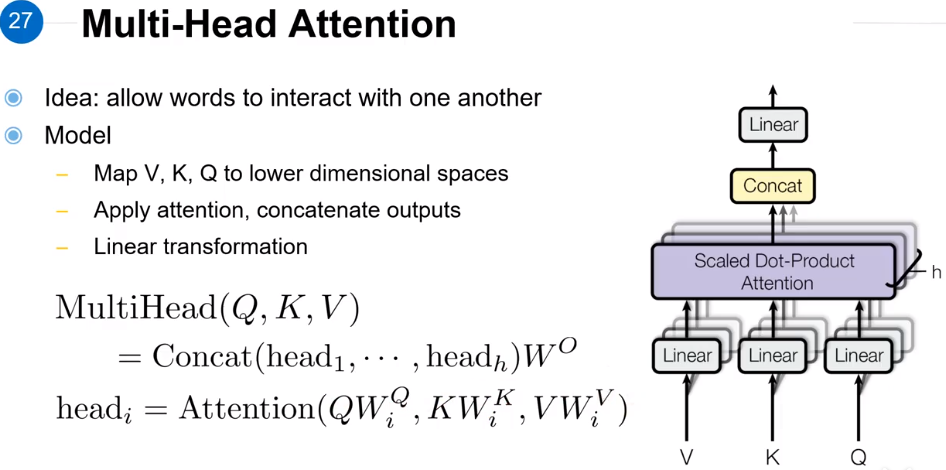
Scaled Dot-Product Attention的h指的是Multi-Head Attention的数量。
Transformer
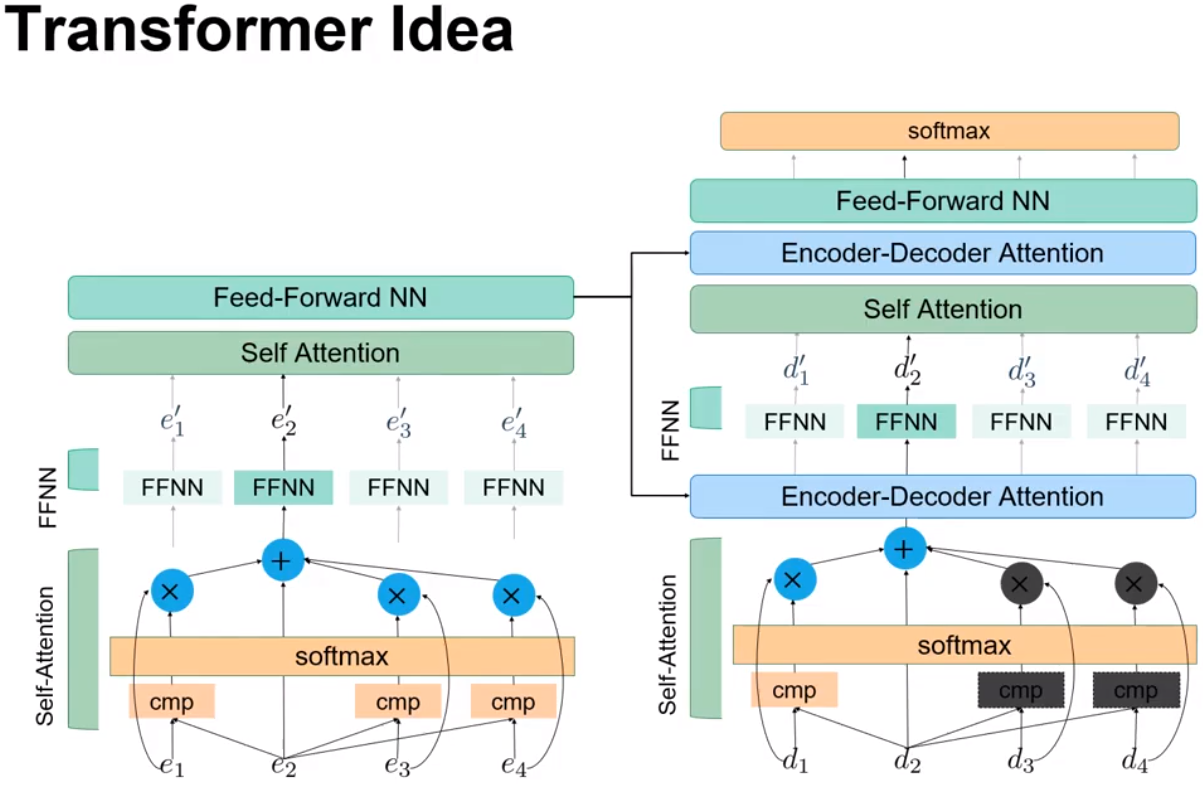
Transformer 就是用 Self-Attention 替换了序列模型的 RNN 单元。
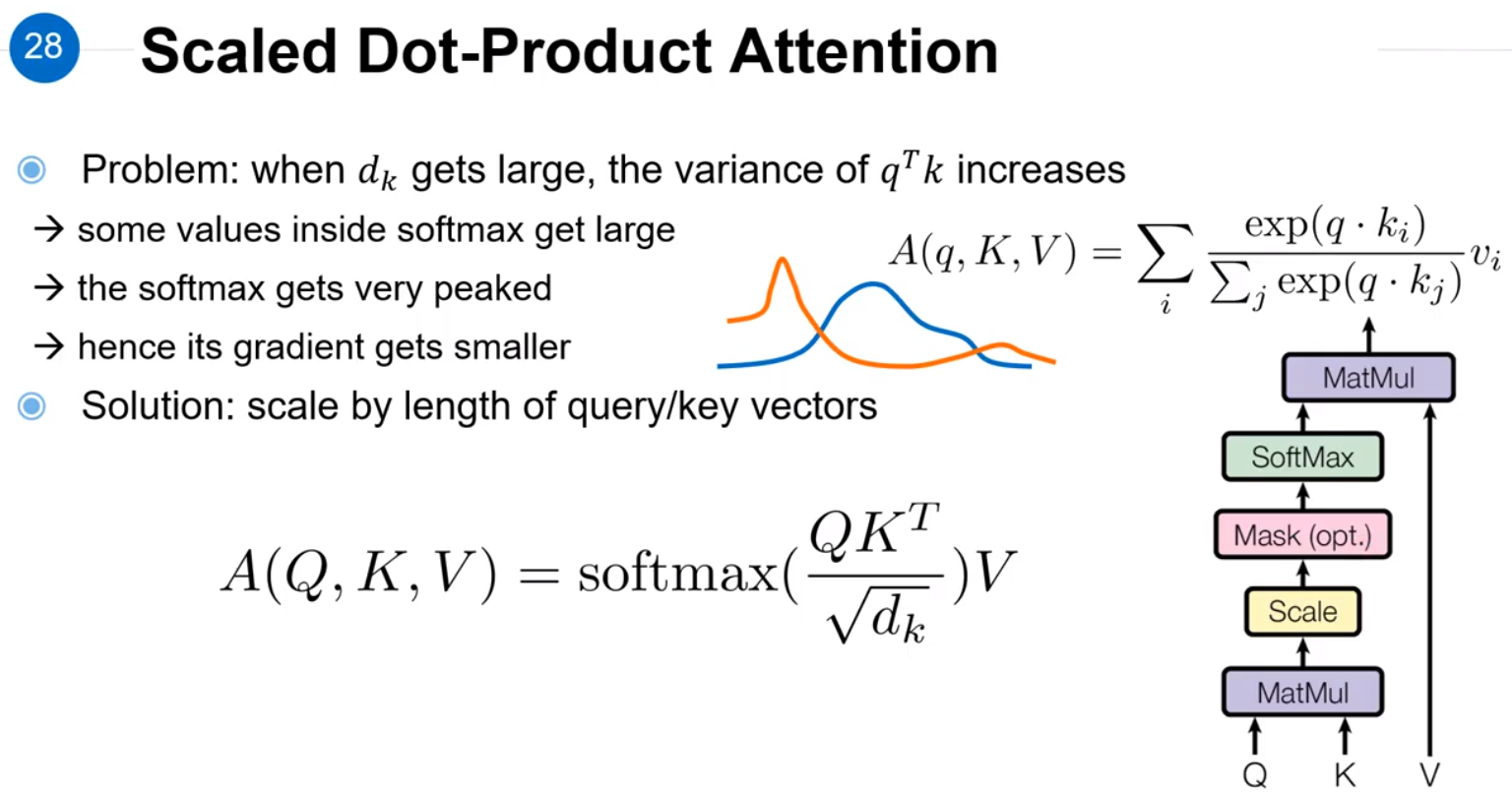
本图主要解释了加入Scaled过程的原因,如上图中间的图像所示,蓝色是 QKTQKT,橙色是 softmax(QKT)softmax(QKT),明显可以看出函数变的很尖,这样导致梯度变得很小,只有高数值的信息才会使模型更新,因此为了解决这个问题,在计算 softmax 之前除以 √dkdk。
这里可以理解为两个独立的矩阵,均值为 0,方差为 1。经过矩阵相乘之后,均值还是 0,方差会变成 dkdk,这样就会导致 Softmax 之后梯度变得很小。
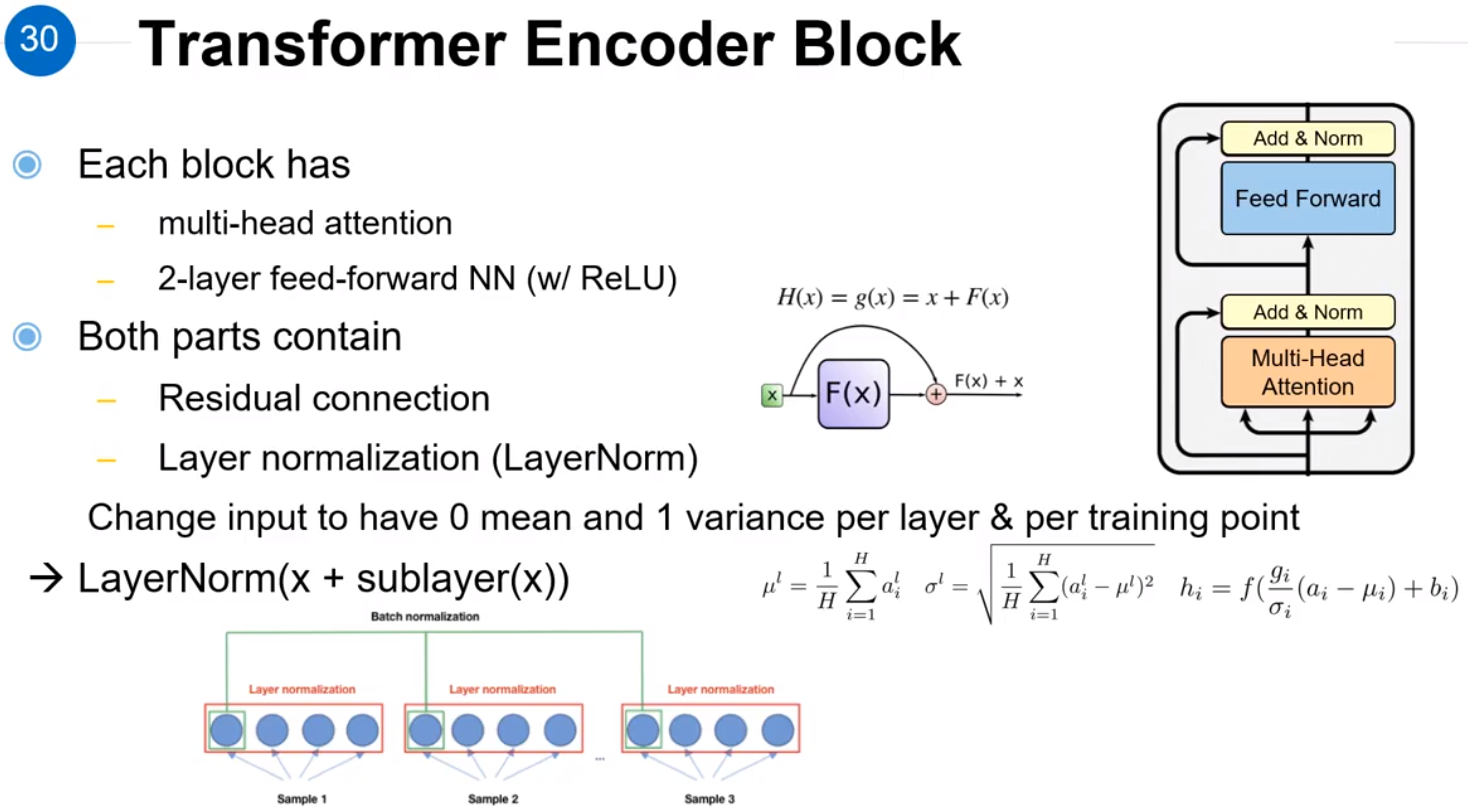
residual connection 是指经过一个 F(x)F(x)后,输出结果是 F(x)+xF(x)+x,这样做的目的是为了解决模型在多次进行 F(x)F(x)计算之后没有更多的signore的时候,模型可以弹性的选择哪部分要经过 F(x)F(x),哪部分可以跳过 F(x)F(x),而且模型也不需要更多的参数来进行训练。
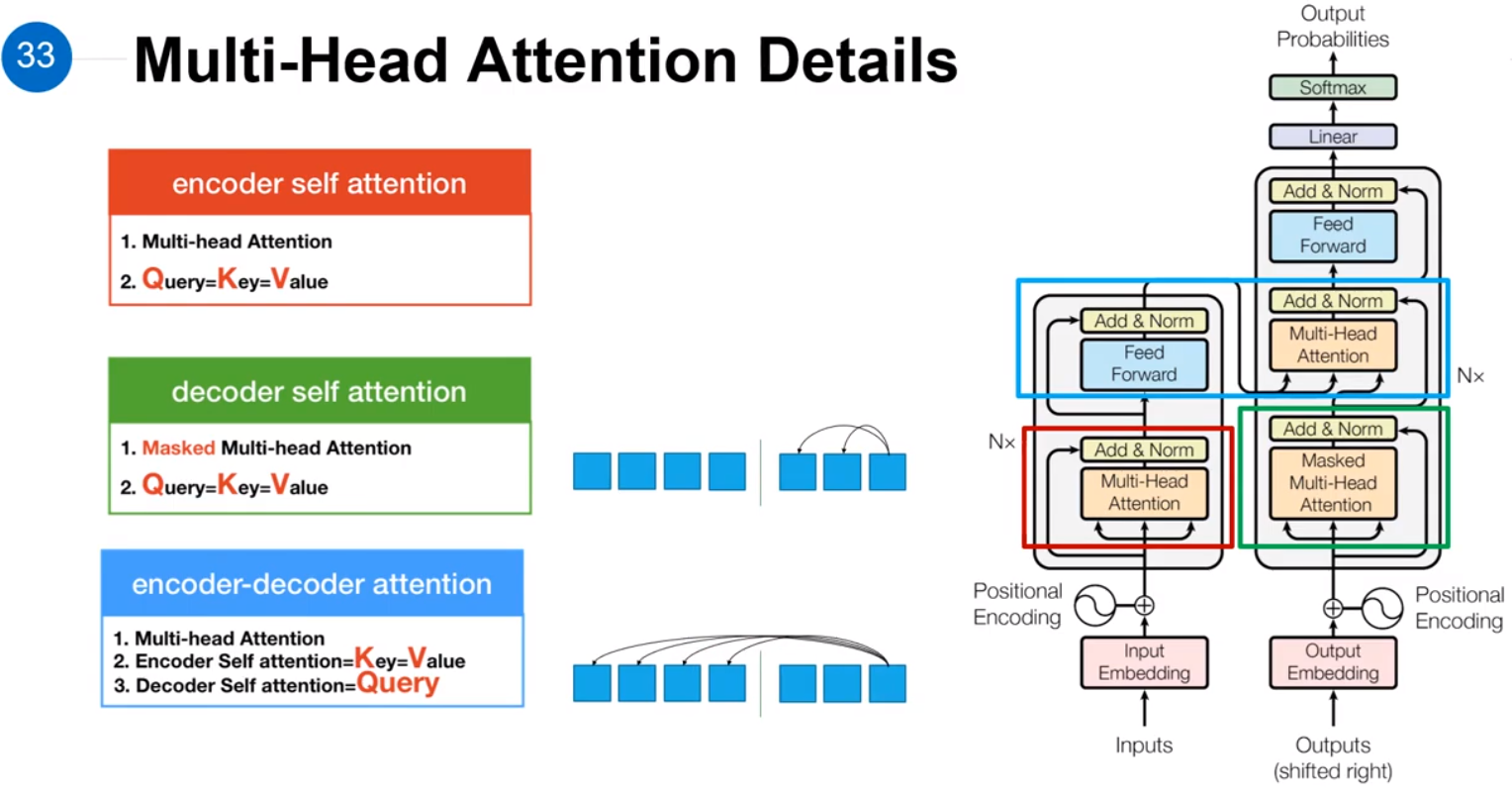
在Decoder中,因为序列的预测过程是从左往右,所以右面单词的Attention是未知的,这就是绿色框中Masked与红色框之间有区别的原因。
在蓝色框中,Decoder提供 Attention 的Query,Encoder提供 Attenion 的Key和Query。
Training Trick

Byte-pair encodings
BPE 算法的基本思路是把经常出现的byte pair用一个新的byte来代替,例如假设('A', ’B‘)经常顺序出现,则用一个新的标志'AB'来代替它们。
例如,假设我们的文本库中出现的单词及其出现次数为{'l o w': 5, 'l o w e r': 2, 'n e w e s t': 6, 'w i d e s t': 3},我们的初始词汇库为{ 'l', 'o', 'w', 'e', 'r', 'n', 'w', 's', 't', 'i', 'd'},出现频率最高的 ngram pair 是('e','s') 9 次,所以我们将’es’作为新的词汇加入到词汇库中,由于’es’作为一个整体出现在词汇库中,这时文本库可表示为 {'l o w': 5, 'l o w e r': 2, 'n e w es t': 6, 'w i d es t': 3},这时出现频率最高的 ngram pair 是('es','t')9 次,将’est’加入到词汇库中,文本库更新为{'l o w': 5, 'l o w e r': 2, 'n e w est': 6, 'w i d est': 3},新的出现频率最高的 ngram pair 是(‘l’,’o’)7 次,将’lo’加入到词汇库中,文本库更新为{'lo w': 5, 'lo w e r': 2, 'n e w est': 6, 'w i d est': 3}。以此类推,直到词汇库大小达到我们所设定的目标。这个例子中词汇量较小,对于词汇量很大的实际情况,我们就可以通过 BPE 逐步建造一个较小的基于 subword unit 的词汇库来表示所有的词汇。
Checkpoint averaging
对训练过程中 checkpoint 保存的模型进行参数平均
Boom Search:
step 1:在预测第一个单词的时候选择前Beam width个概率最大的单词作为第一个单词;step 2:假设词汇表长10000,B=3按照 P(y<1>,y<2>|x)=P(y<1>|x)P(y<2>|x,y<1>)P(y<1>,y<2>|x)=P(y<1>|x)P(y<2>|x,y<1>)最大,就会在开头为(y<1>,y<2>)(y<1>,y<2>)的30000种选择中选取概率最大的3种,并将(y<1>,y<2>)(y<1>,y<2>)作为新的开头;step 3:将step 2中选取的新的开头作为条件,重复计算step 2,如果遇到终止符则停止。
改进集束搜索(改进其打分规则):
由于,是多个小于 1 的概率相乘,最终得到的数值会很小很小,出现数值下溢,因此对上述公式取对数:
argmaxTy∑t=1log,P(y|x,y1,…,yt−1)argmax∑t=1Tylog,P(y|x,y1,…,yt−1)
但是 log 函数在(0,1)是负数,序列越长数值越低,所以模型会更倾向于短文本输出而不是简洁的文本。于是第二次改进:
1TαyTy∑t=1log,P(y|x,y1,…,yt−1)1Tyα∑t=1Tylog,P(y|x,y1,…,yt−1)
对和函数进行归一化,但是不是单纯的除以单词数量,而是除以 TyTy 的 αα 次幂,这里的 αα 是一个超参数。
