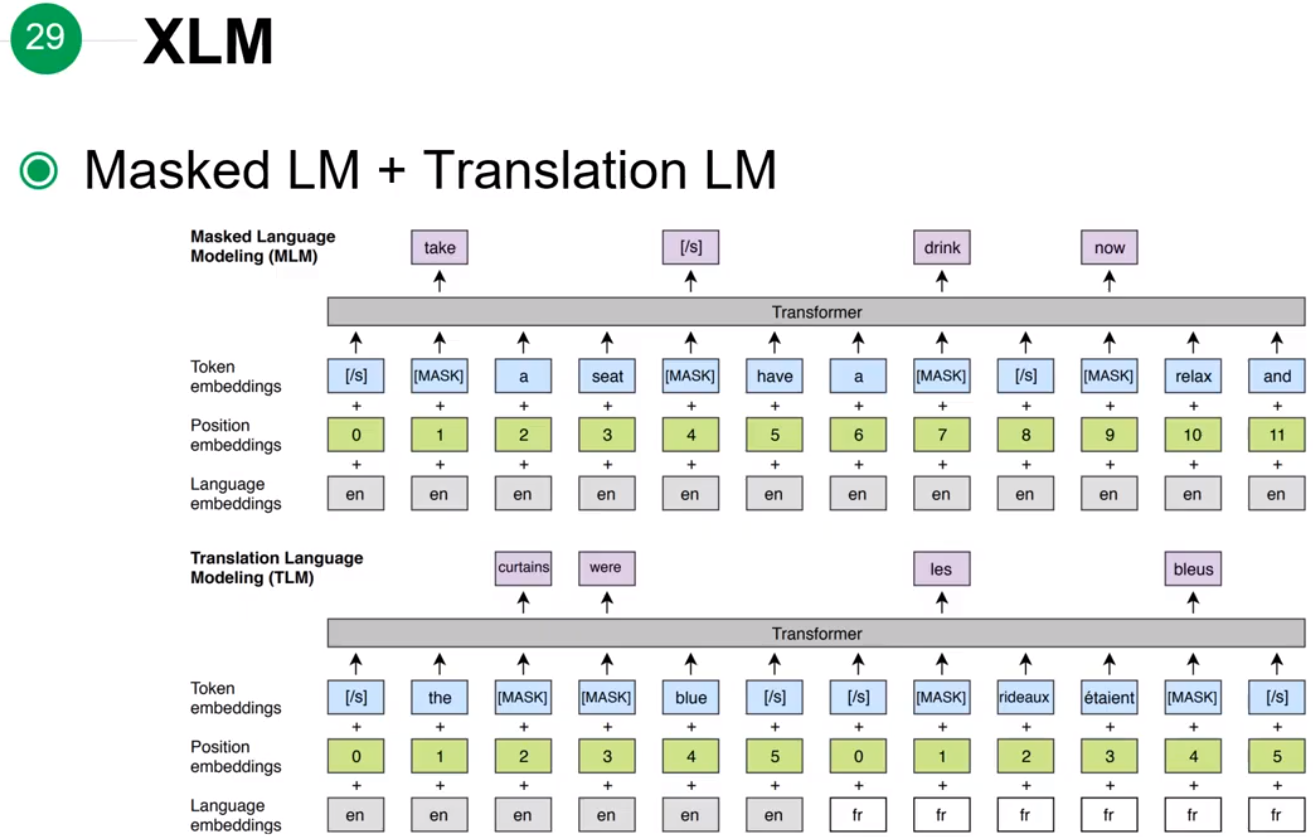
本文主要是针对近年来序列模型的发展,例如 BERT、Transformer-XL、XLNet、RoBERTa 以及 XLM 等模型的思路整理。
BERT: Bidirectional Encoder Representations from Transformers
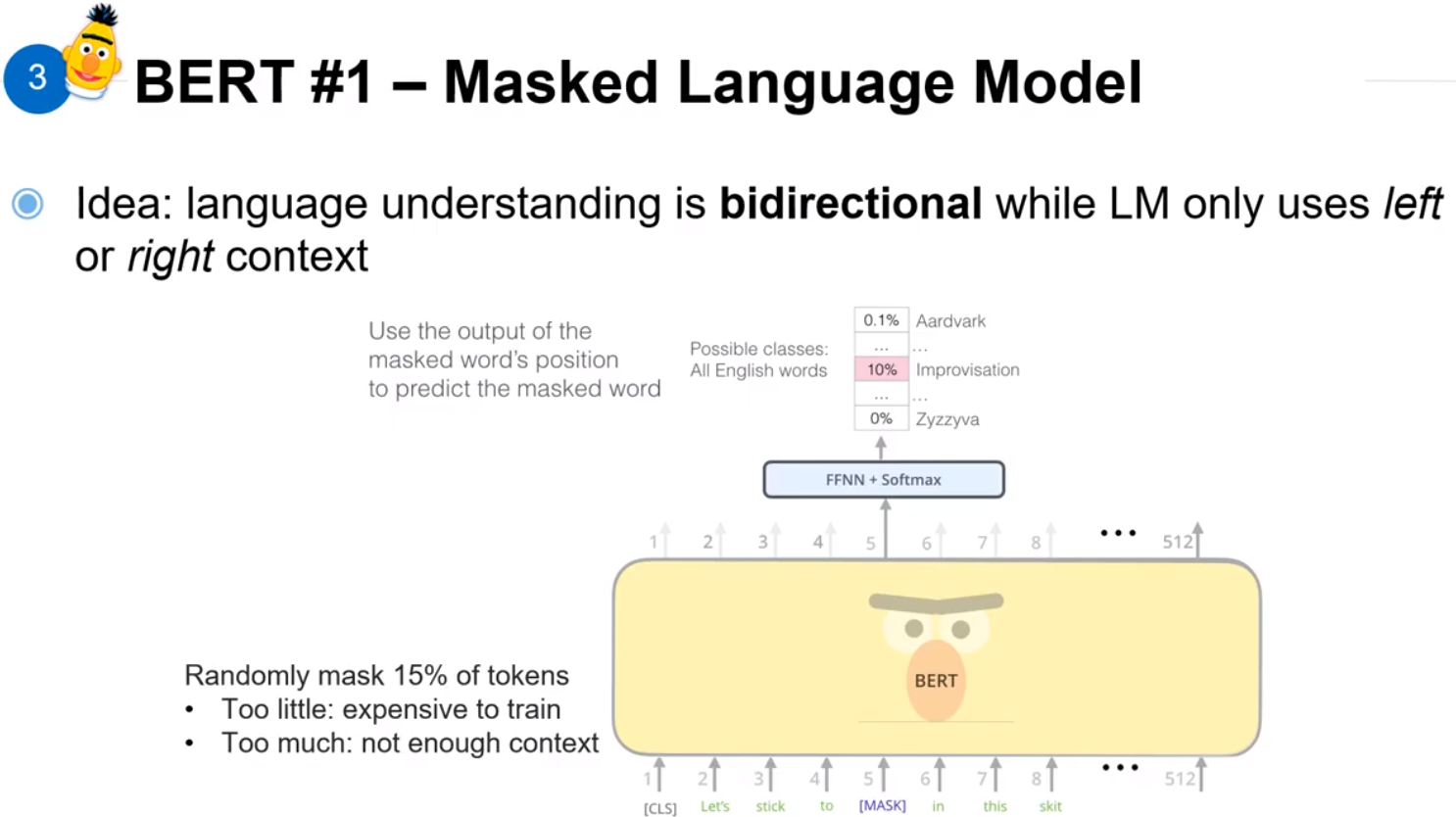
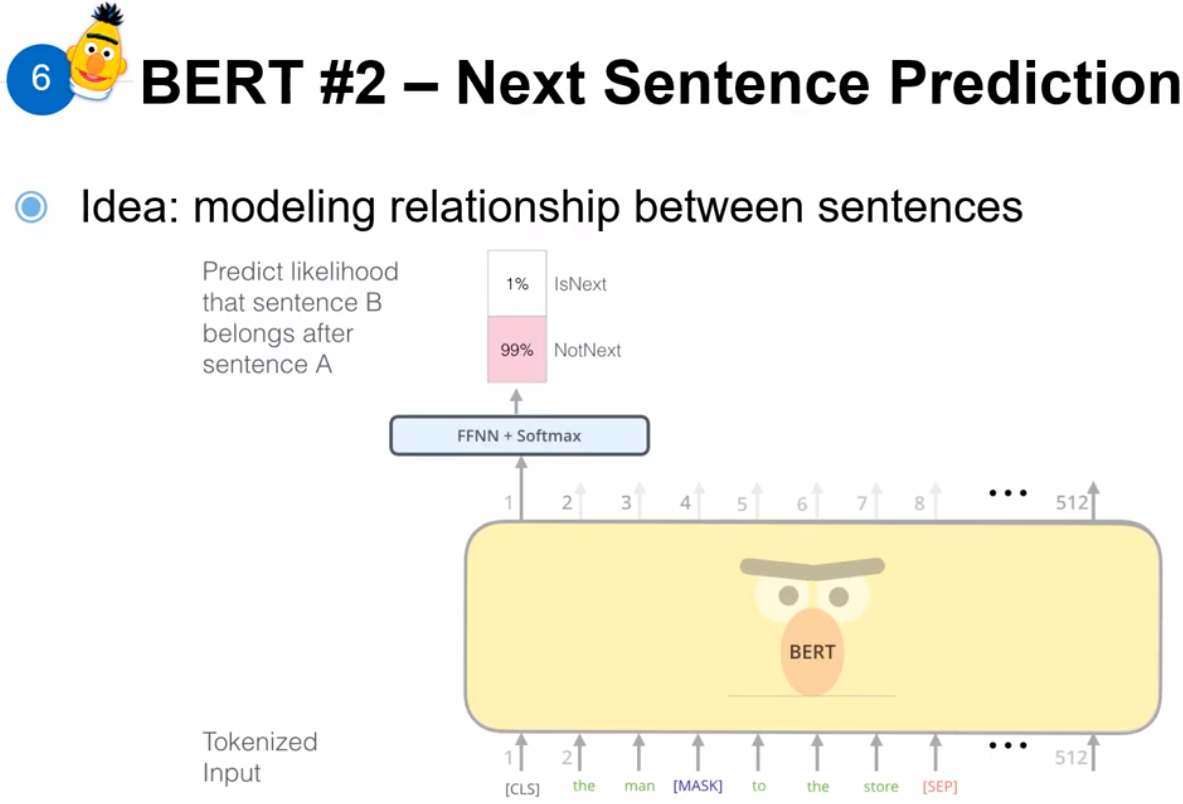
上图是 BERT 提出的主要的两个点。

选择encoder哪一层的信息会比较好呢?上图给出了解答。不难看出,后四层的encoder层sum之后得到了当前维度的最高F1,而concat后四层发现F1又有所提高,所以综合来看选择encoder的后几层的效果会比较好。
Transformer-XL
超长输入的文本会被原始的 transformer 切掉,而且如果进行切分的时候也没有很好的解决切分的边界问题。Transformer-XL就是要解决这个问题。
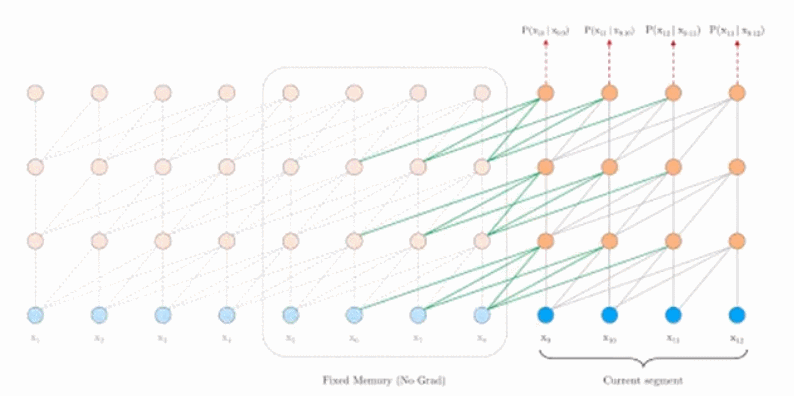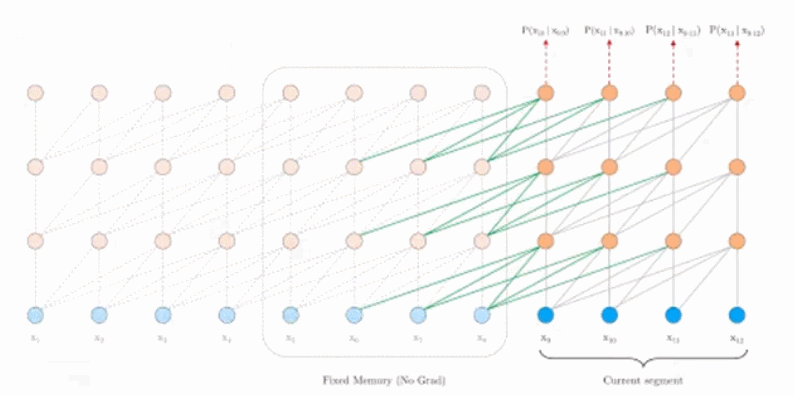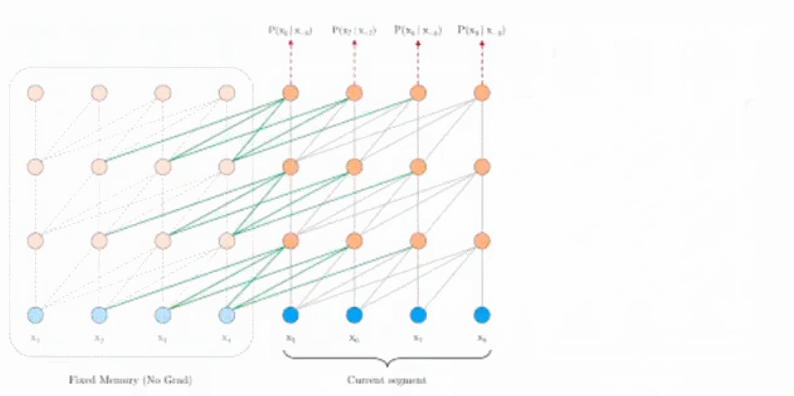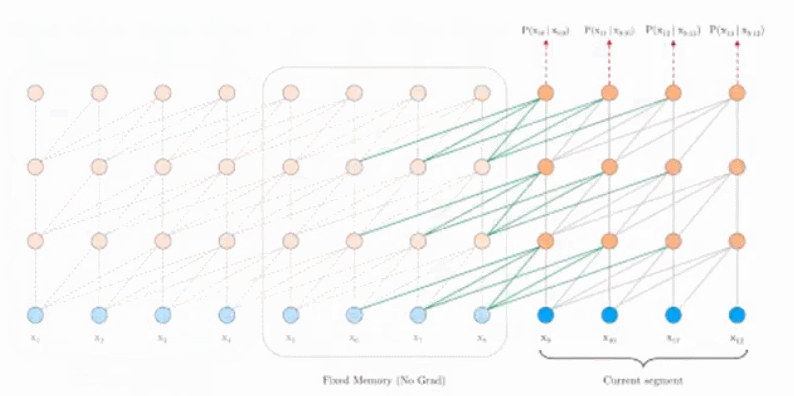
Tranformer-XL的解决方式如上图所示,在训练下一个segment时,从上一个segment读取参数进行重用,这样可以使得dependency的长度可以扩展到N倍,N是神经网络的深度。
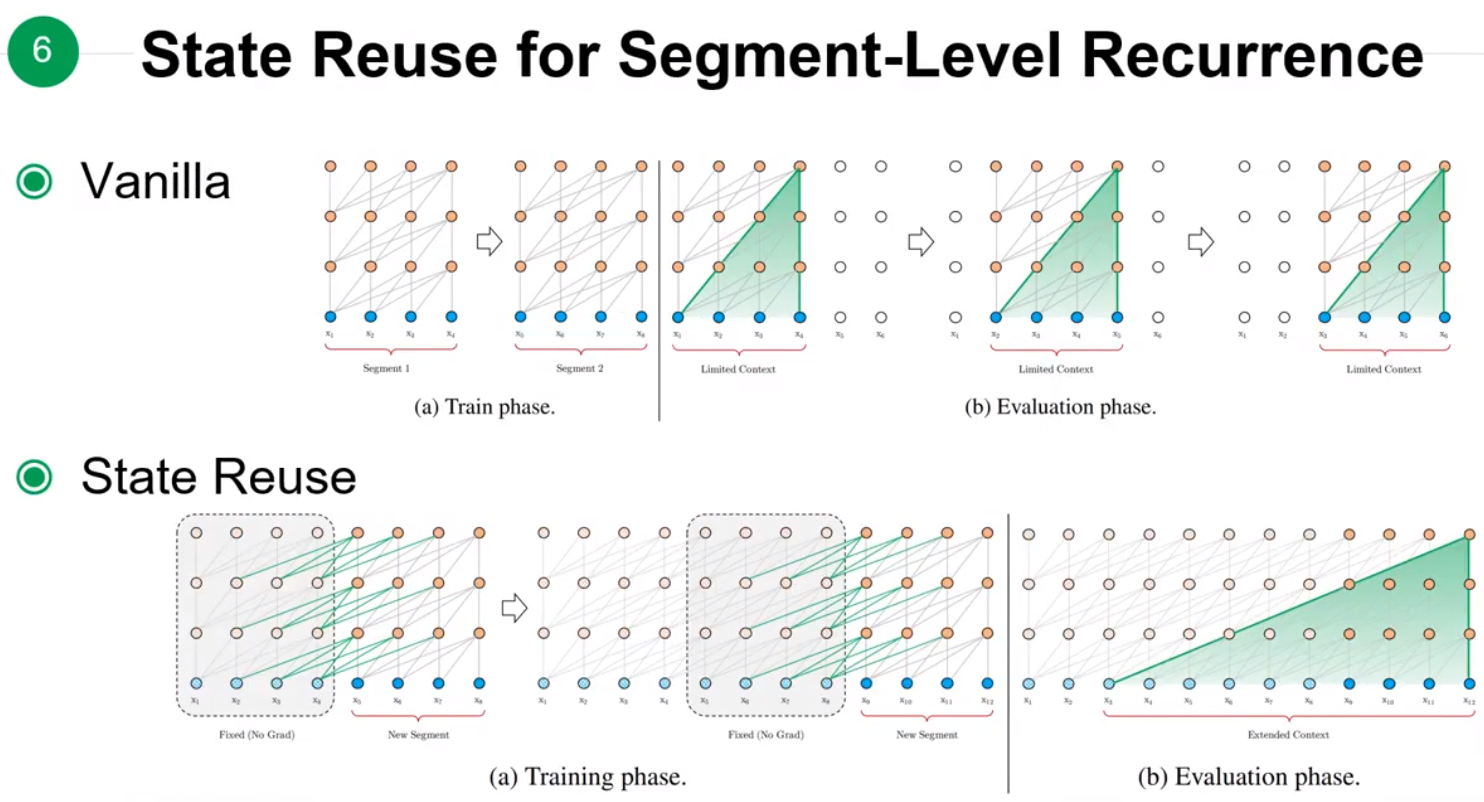
模型优点的比较:在Vanilla版本Train phase时,两个segment是互相独立的,在跨越两个seqment的dependency就没有被考虑;而在Evaluation时,如果要输出的长度为 6,而学习的一个segment只有 4 的时候,就会出现预测的序列只能看到前后 4 个点的权值。
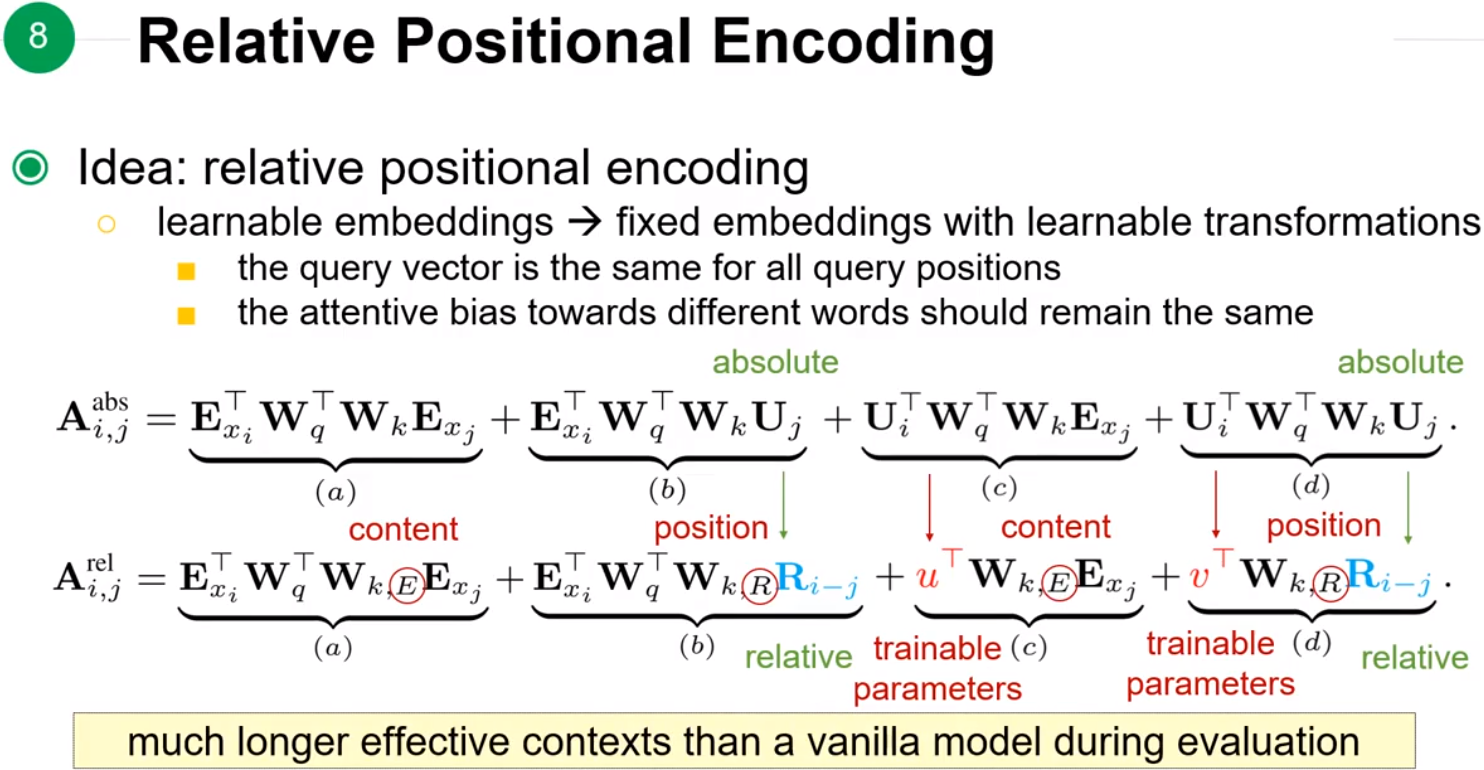
让模型去考虑相对位置的关系,而不是绝对位置的关系。ExiExi 是word embedding,UiUi 是position embedding,在相对位置关系中会选定一个基准点作为基准向量 uTuT、vTvT,然后用 Ri−jRi−j 来表示 i,ji,j 两个位置之间的差异,这里 uT,vT,Ri−juT,vT,Ri−j 都是需要训练的。

XLNet:Generalized Autoregressive Pretraining for Language Understanding
在说 XLNet 之前要先提一下 AR 和 AE 模型的概念。
Auto-Regressive(AR)
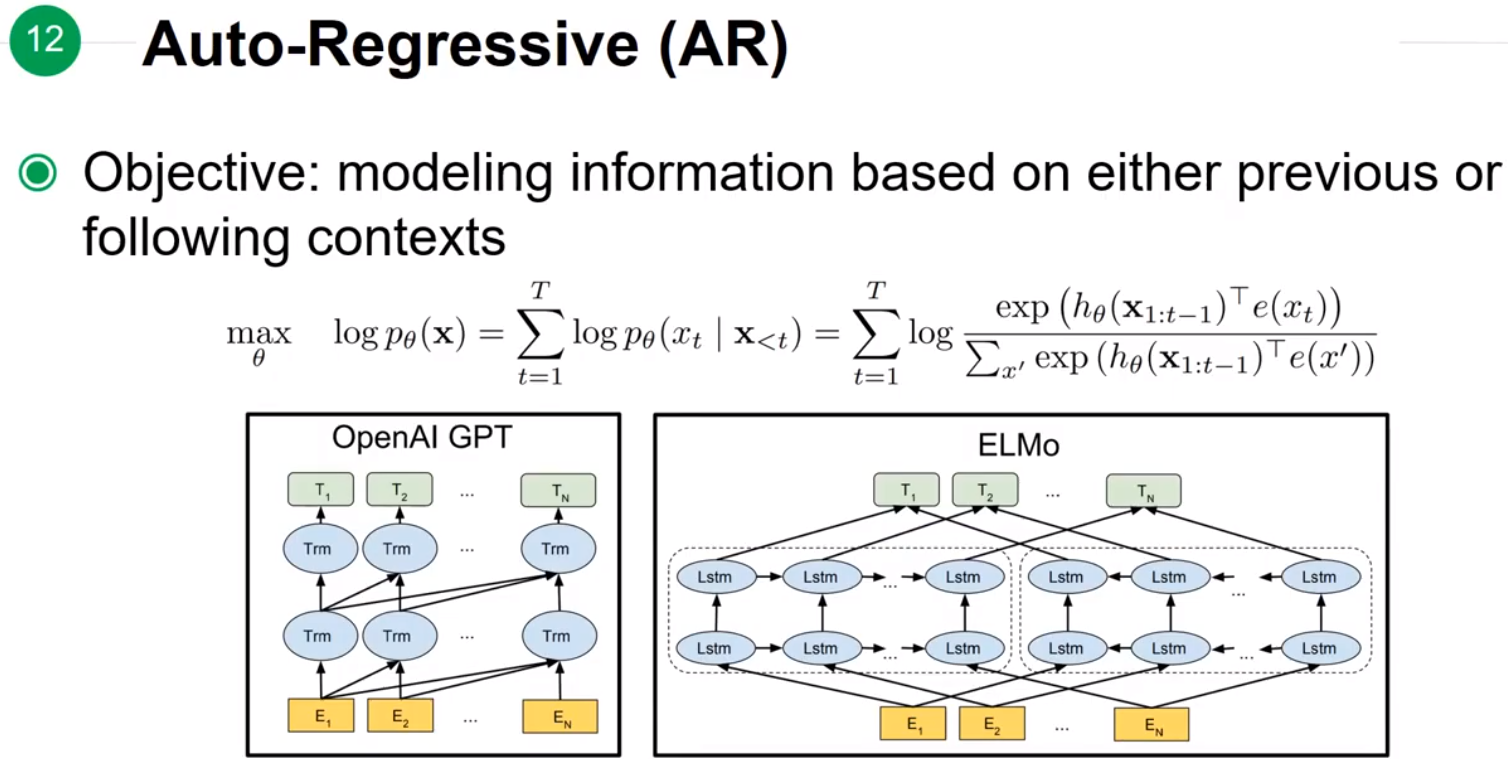
模型在预测 XtXt 的时候,只会看到前半部分或者后半部分考虑的information。
Auto-Encoding(AE)
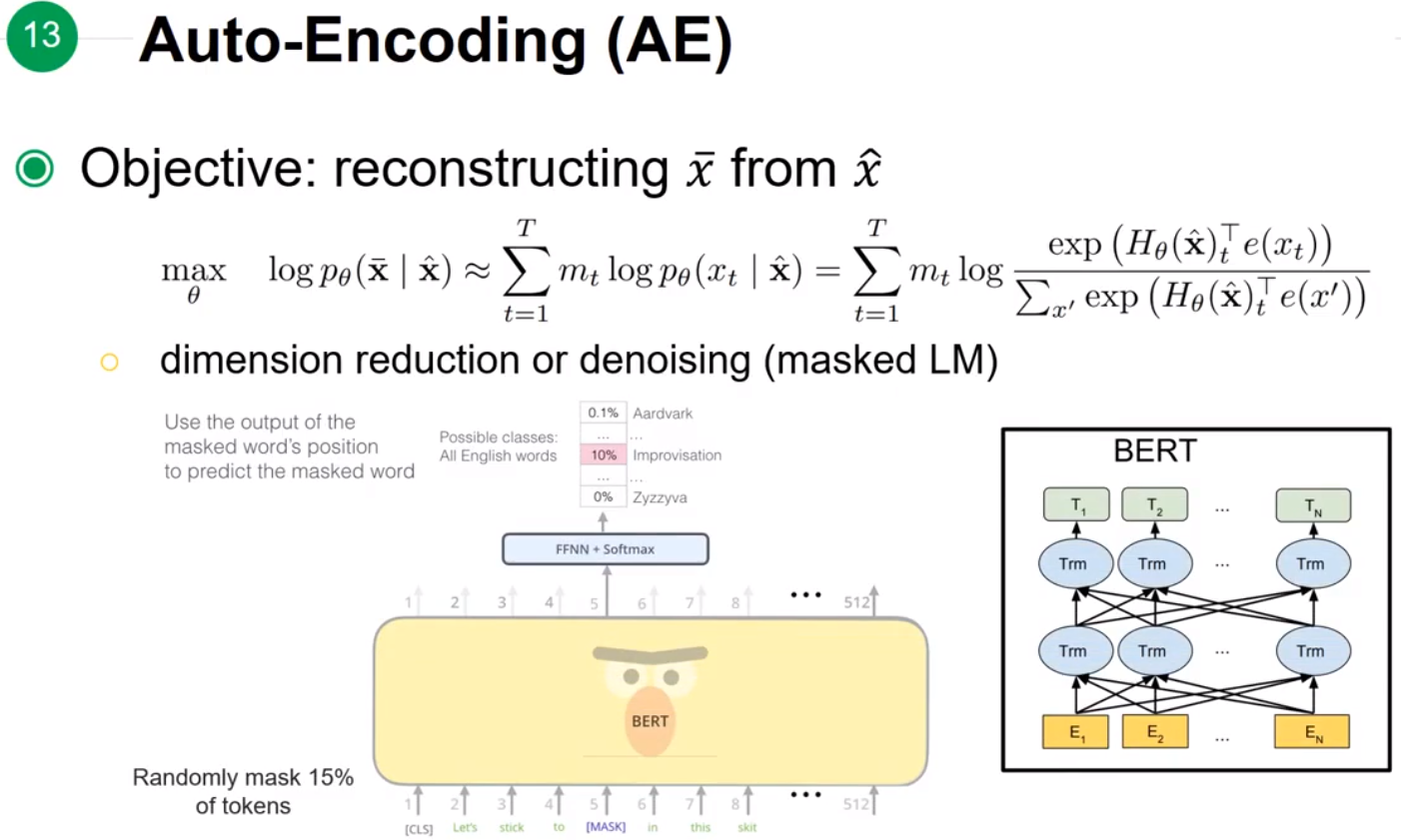
从一个有noise的样本预测原本的值,是可以看到左右两部分的信息。
AE 存在的问题是:
-
AE 模型认为不同位置的
[MASK]是互相独立的,认为模型预测前一个[MASK]的词不会影响到后一个[MASK],但是实际上是有可能两个位置的[MASK]互相关联。 -
在
pre-training和fine-tuning之间存在差异。具体表现在pre-training过程中有[MASK]标签,而在fine-tuning过程中是没有[MASK]的,这就存在了一种input noise的情况。
XLNet
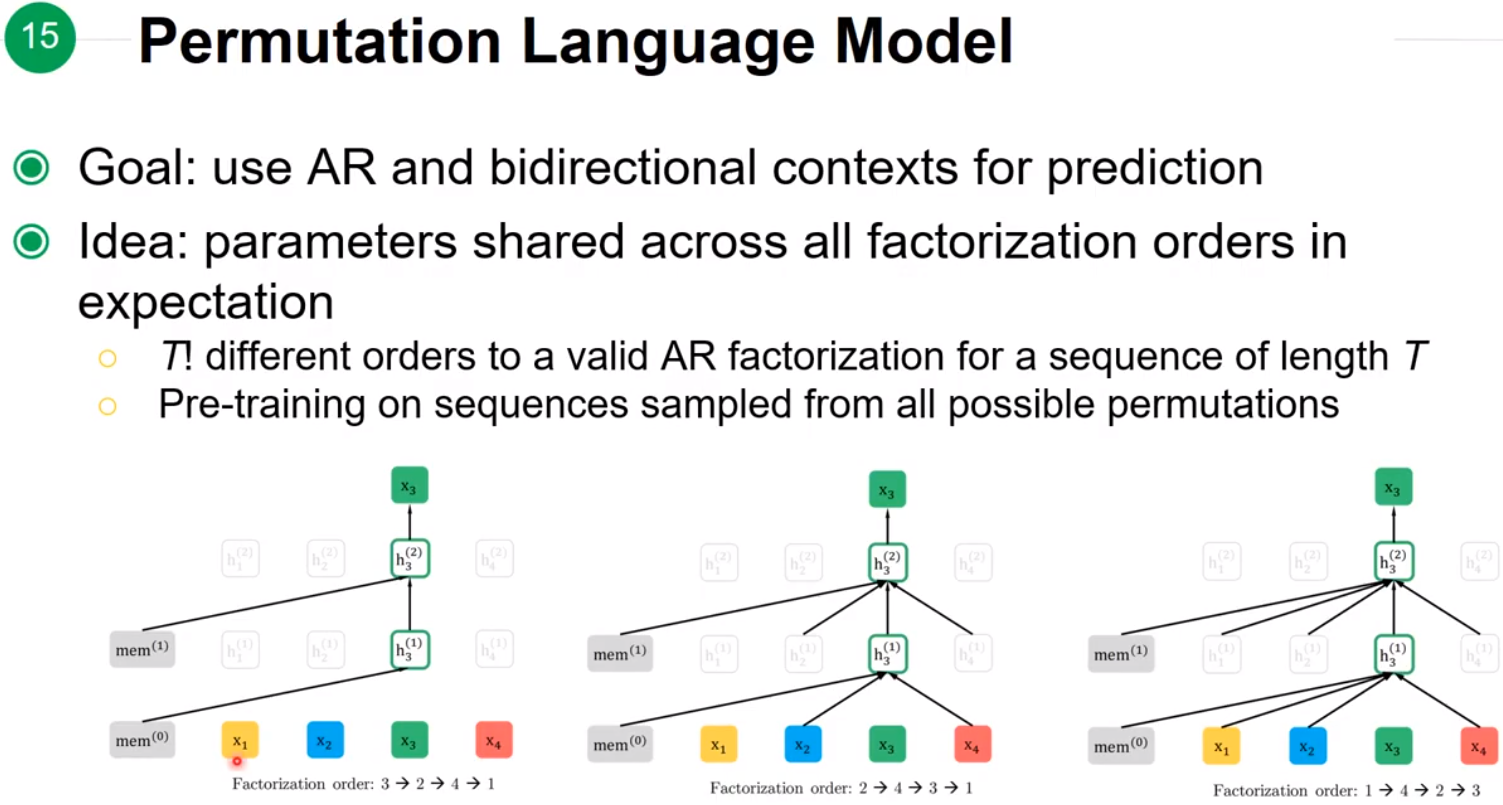
XLNet 目标是使用 AR 模型,但同时也能够使用bidirectional contexts。方法是随机排列这段sequence的每个单词,让模型去学习每个随机后的sequence,这样在第 tt 个位置之后的信息也有可能随机到 tt 前面而被模型学习到。
例如图中三种情况:
-
序列为
3-2-4-1:以 3 为例,此时 3 为开头,模型只能看到起始符,看不到其他任何符号; -
序列为
2-4-3-1:以 3 为例,此时 3 可以看到 2 和 4; -
序列为
1-4-2-3:以 3 为例,此时可以看到序列的全部其他信息(1,4,2)。
实现细节
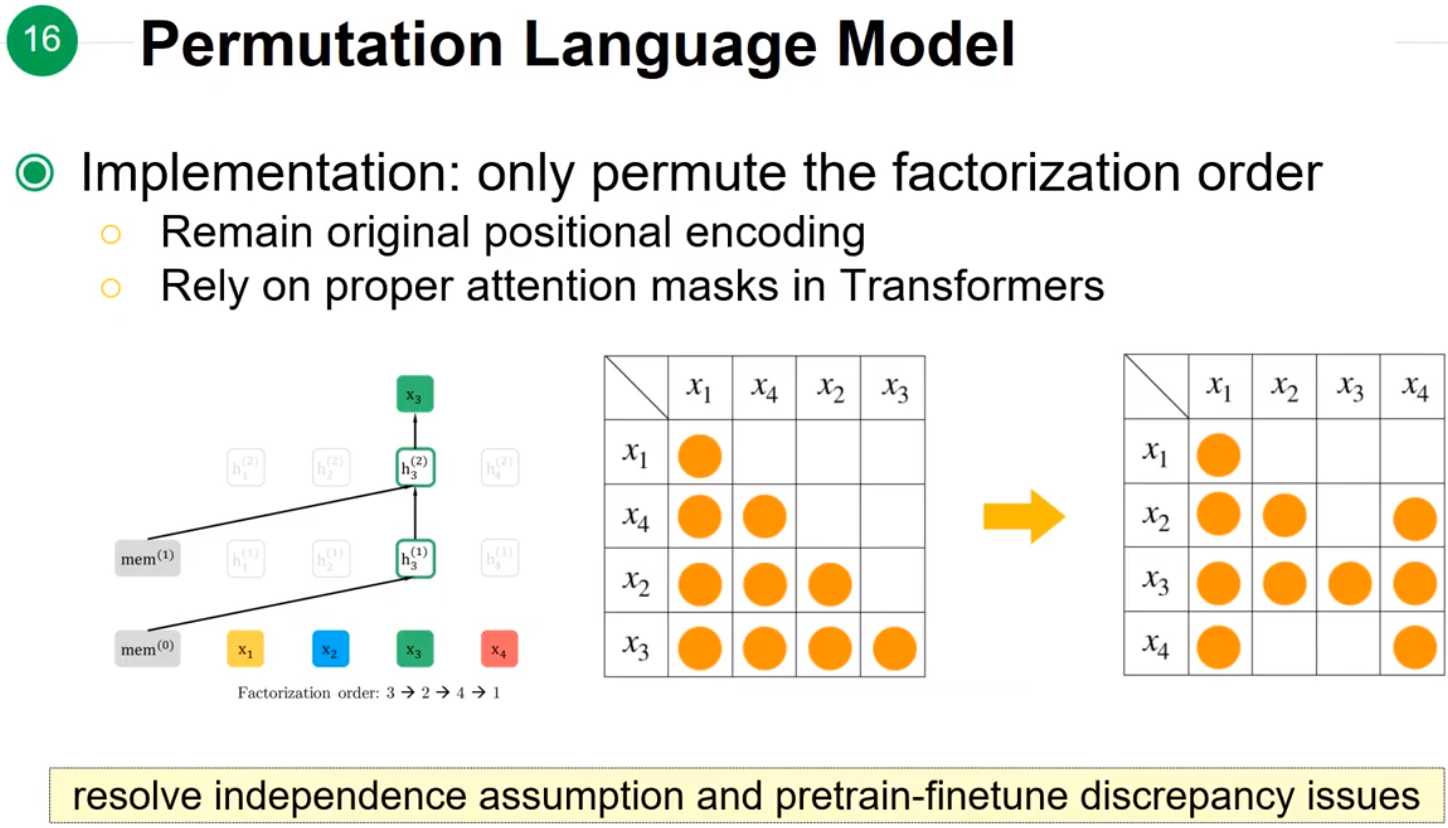
上述的乱序过程实质上就是改变了每个节点的Attention可以看到哪些节点的信息,也就是改变了Attention mask矩阵的值。因此在实现Positional Encoding时,没有打乱 x1,…,x4x1,…,x4 的顺序,而是将每个节点可以看到的信息依次填入了正常的Positional Encoding矩阵。

但是实现这种随机乱序存在的问题是模型不知道 P(x3|x1,x2)P(x3|x1,x2)和 P(x4|x1,x2)P(x4|x1,x2)的区别,模型不知道预测的下一个token是第三个位置的还是第四个位置的,为了解决这个问题就引入了Two-Stream Self-Attnetion来引入position信息 ztzt。
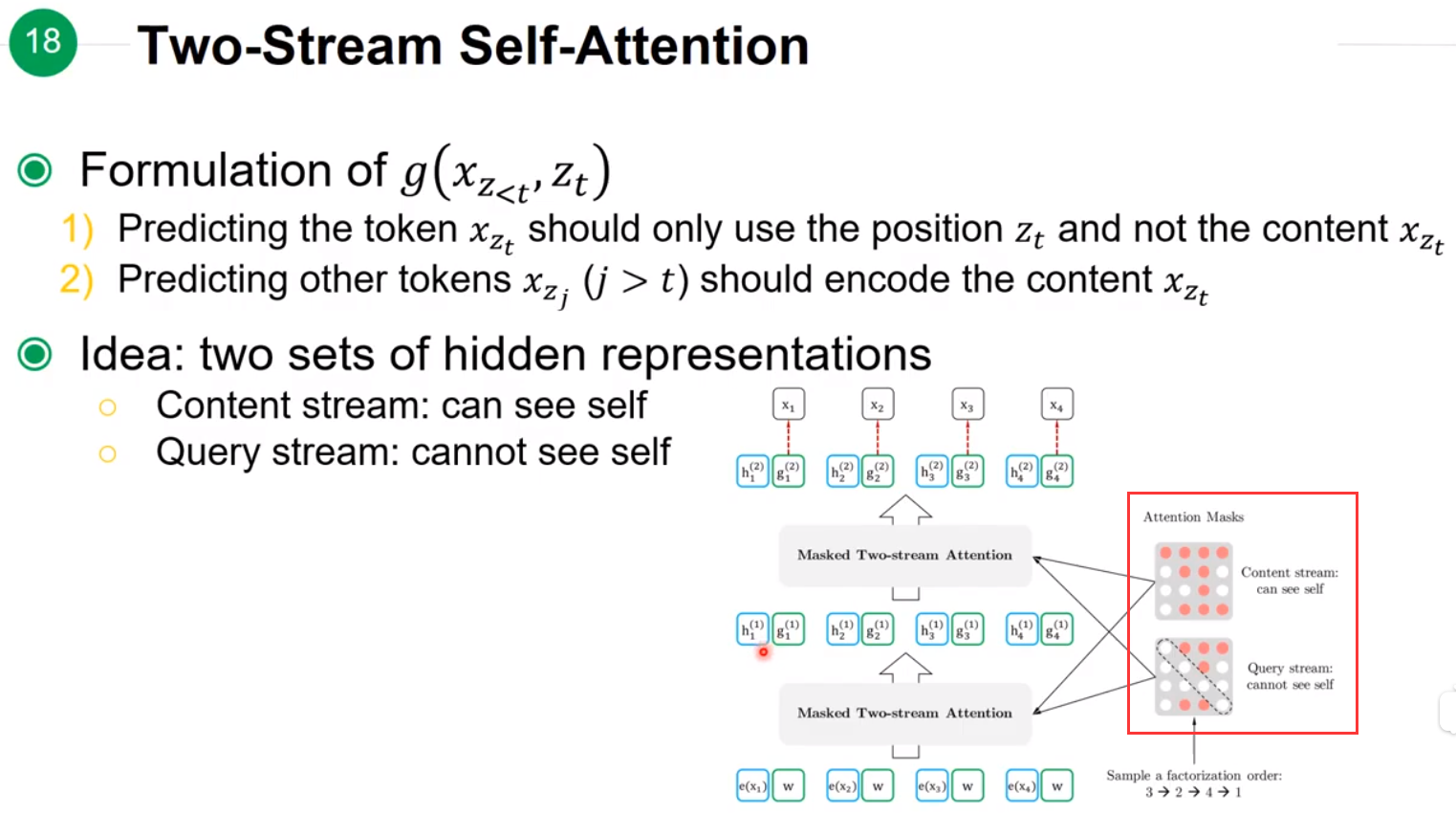
两个Stream分别是能看到自身的Content streamhh 和不能看到自身的Query streamgg。
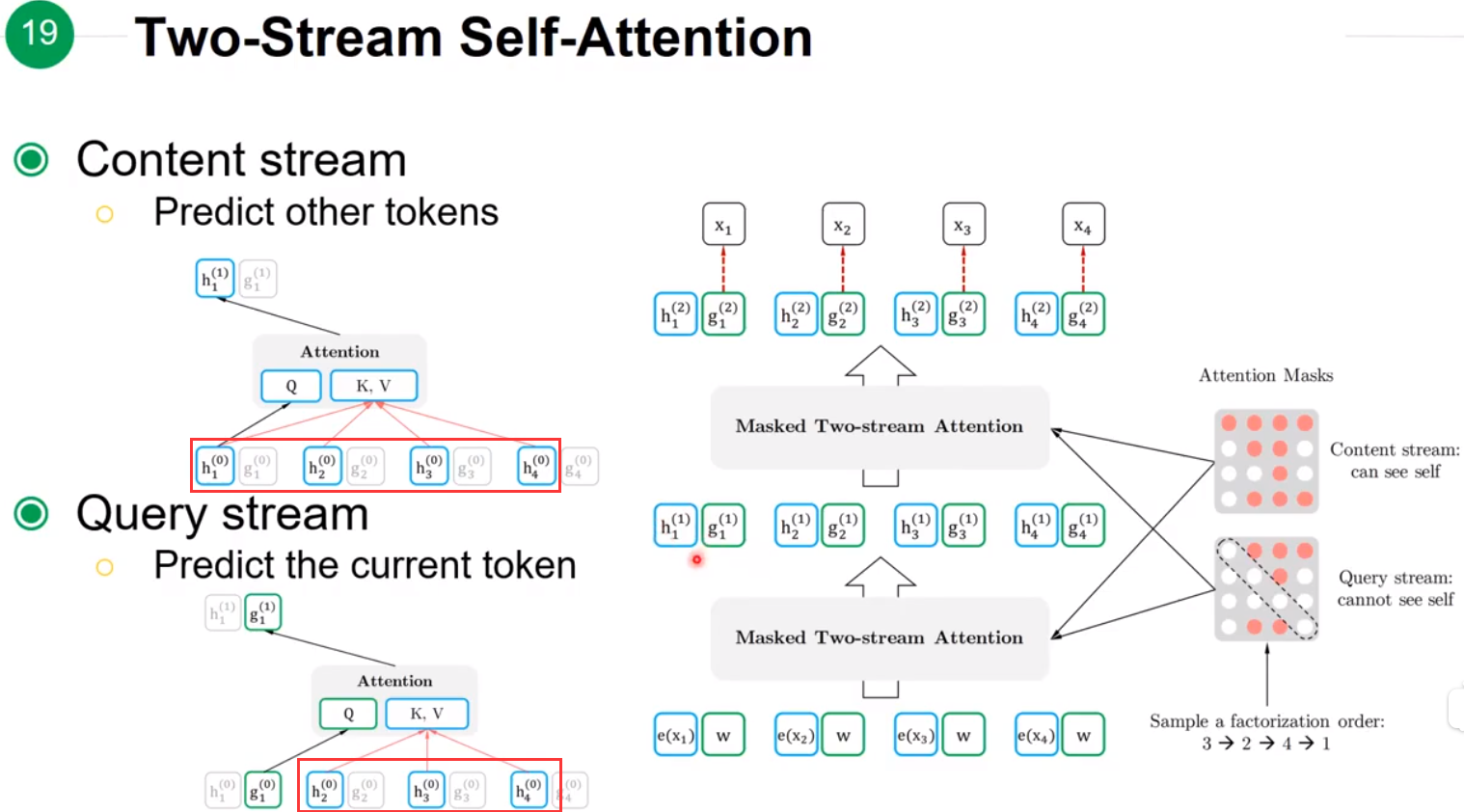
上图能够更清楚的展示出Content stream和Query stream的区别。最终模型在pre-training阶段时,因为sequence中存在[MASK],所以就使用Query stream来学习信息;在fine-tuning时由于可以看到所有的输入所以就使用Content stream。
个人理解:XLNet 利用两种Attention来解决pre-training和fine-tuning阶段中存在的input noise问题,在预测[MASK]位置的信息时使用Query stream,在预测其他位置的信息时使用Content stream。

RoBERTa:A Robustly Optimized BERT Pretraining Approach

Contributions:
-
pre-training 使用十次不同的 mask 结果;
-
调参;
-
增大数据量,只训练完整的序列。(个人感觉最大的优点,数据量大)
下面是 BERT 模型的其他变种:
SpanBERT: Improving Pre-training by Representing and Predicting Spans

XLM: Enhancing BERT for Cross-lingual Language Model